






Ollama is een open-source applicatie waarmee gebruikers AI-modellen lokaal of op je eigen dedicated servers kunnen hosten en beheren, bijvoorbeeld GPT-Oss, Qwen of DeepSeek.
In deze handleiding laten we zien hoe je Ollama installeert, een LLM configureert en vervolgens gebruik van maakt via Ollama's REST API.
Vereiste hardware
Voor het hosten van LLM's is vaak stevige hardware nodig; bij voorkeur gebruik je een of meerdere stevige GPUs, maar het is ook mogelijk om LLMs enkel op RAM te laten werken. Let wel dat je performance dan ongeveer 10-50x trager is vergeleken met het gebruik van dedicated GPUs.
Om de hardware vereisten te verlagen kun je gebruik maken van ‘quanitzed’ modellen. Simpel gezegd comprimeer je een LLM door quantization toe te passen. Je levert dan een minimaal beetje accuratie in voor een aanzienlijke vermindering in vereiste hardware. De dynamic-quantized modellen van Unsloth zijn hier een hele goede optie voor. Pro-tip: bekijk ook eens Unsloth-studio.
In de tabel hieronder geven we een voorbeeld van verschillende hoeveelheid parameters en de hoeveelheid vRAM (of RAM, of een combi van beide) die je nodig hebt bij gebruik van Unsloth quantization voor Qwen3.5.
Qwen3.5 |
3-bit | 4-bit | 6-bit | 8-bit | BF16 |
| 0.8B + 2B | 5 GB | 9 GB | |||
| 4B | 7 GB | 10 GB | 14 GB | ||
| 9B | 19 GB | ||||
| 27B | 24 GB | 54 GB | |||
| 35B-A3B | 70 GB | ||||
| 122B-A10B | 245 GB | ||||
| 397B-A17B | 810 GB |
Ollama installeren en gebruiken
Stap 1
Linux (Ubuntu, AlmaLinux etc)
Je download en installeert Ollama eenvoudig met één commando:
curl -fsSL https://ollama.com/install.sh | shWindows
Download Ollama via de knop hieronder. Start het gedownloade bestand en klik op ‘Install’.

MacOS
Download Ollama via de knop hieronder. Start het gedownloade bestand en klik op ‘Install’.
Stap 2
Ollama wordt automatisch uitgevoerd. In het geval van Linux betekent dit dat je vanuit de terminal direct Ollama een commando kunt geven. In Windows moet je de command prompt starten (Windows start-knop > cmd) en in MacOS een terminal.
Nu installeer je eenvoudig het gewenste model met het commando:
ollama run <modelnaam>:<parameters>Bijvoorbeeld voor Qwen3.5:27b
ollama run qwen3.5:27bJe kunt optioneel wisselen welk model je gebruikt door simpelweg het model aan te passen en het commando nogmaals uit te voeren.
Sluit tot slot de Ollama-terminal-sessie met het commando:
/byeJe kunt nu direct gebruik maken van Ollama! Wil je vanaf een ander apparaat Ollama gebruiken? Lees dan eerst de volgende paragraaf.
Ollama gebruiken vanaf een ander apparaat
Het is mogelijk Ollama te gebruiken vanaf een ander apparaat dan het apparaat waarop je Ollama hebt geïnstalleerd. Hiervoor is een kleine aanpassing nodig in de configuratie van Ollama.
Als je deze optie gebruikt, raden we aan om de beveiliging van je server niet te vergeten. Stel bijvoorbeeld een IP-restrictie in je firewall in voor poort 11434 (de poort die Ollama gebruikt) zodat je enkel vanaf je eigen IP-adres(sen) toegang hebt. Eventueel kun je dit combineren met een eigen VPN-server.
Linux
Stap 1
Open de Ollama-service-configuratie:
nano /etc/systemd/system/ollama.service
Stap 2
Voeg onder het blok [Service] de volgende twee regels toe:
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"Sla de wijzigingen op en sluit het bestand (ctrl + x > y > enter).
Stap 3
Herlaad systemd en herstart Ollama om de wijzigingen te verwerken:
systemctl daemon-reload
systemctl restart ollamaJe kunt nu ook vanaf een ander apparaat gebruik maken van Ollama, bijvoorbeeld vanaf je telefoon, zie de volgende paragraaf.
MacOS
Voer de volgende commando's uit en herstart daarna de Ollama applicatie:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"Je kunt nu ook vanaf een ander apparaat gebruik maken van Ollama, bijvoorbeeld vanaf je telefoon, zie de volgende paragraaf.
Windows
Stap 1
Sluit Ollama af. Onderaan rechts op de taakbalk is er een icoontje (mogelijk verborgen onder het pijltje omhoog) waar je met de rechter muisknop op kunt klikken en vervolgens ‘Quit Ollama’ kunt selecteren om het af te sluiten.
Stap 2
Druk tegelijkertijd op je toetsenbord op het Windows Start-icoon + R. Het uitvoeren/run-scherm verschijnt. Type hier het commando 'sysdm.cpl' en druk op 'OK' of de enter-toets.
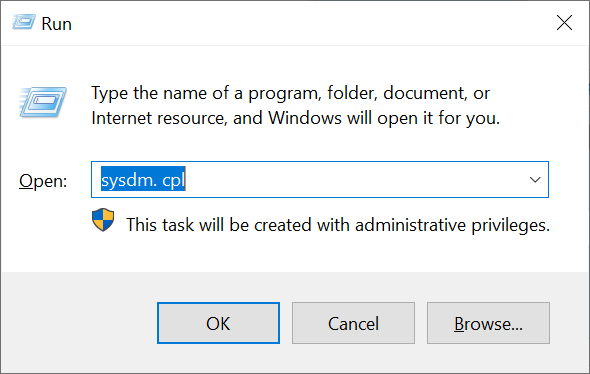
Stap 3
Klik op het tabblad 'Advanced' > 'Environment Variables'.
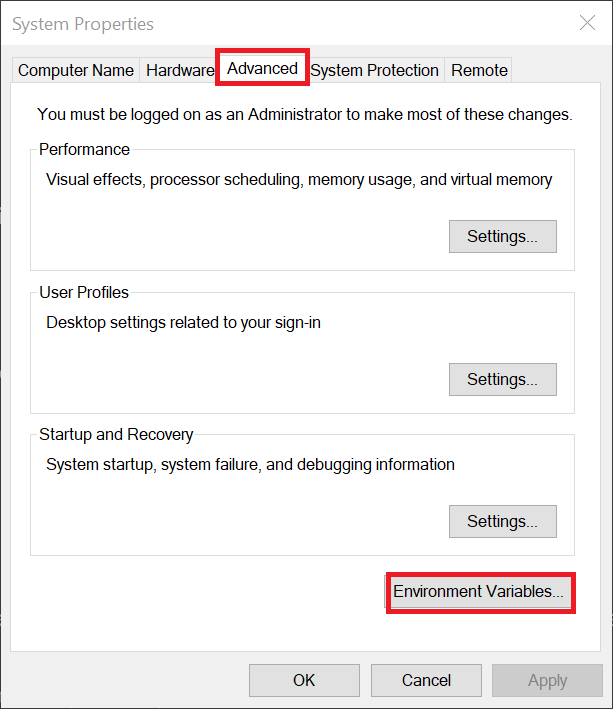
Stap 4
Klik onder ‘User variables for <jegebruikersnaam>’ op ‘New…’.

Een ‘New User Variable’-pop-up-venster verschijnt. Gebruik als ‘Variable name’ de naam ‘OLLAMA_HOST’ en als ‘Variable value’ de waarde ‘0.0.0.0’ en klik op ‘OK’

Herhaal deze stap en voeg deze keer een variabele toe met de naam ‘OLLAMA_ORIGINS’ en de waarde ‘*’.
Start tot slot Ollama opnieuw op. Je kunt nu ook vanaf een ander apparaat gebruik maken van Ollama, bijvoorbeeld vanaf je telefoon, zie de volgende paragraaf.
Je Ollama-hosted LLM gebruiken
Het moment waar je op zat te wachten is aangebroken: het gebruik van Ollama. Er zijn meerdere opties beschikbaar om Ollama te gebruiken, maar we raden er drie aan:
- OpenWeb UI: met Open WebUI voeg je een laag
- Chatboxai: een chat programma enigszins vergelijkbaar met ChatGPT, maar dan enkel met chatfunctionaliteit
- API: jouw self-hosted LLMs zijn via een REST API beschikbaar
ChatboxAI
ChatboxAI is een AI client applicatie waarmee je eenvoudig verbindt met vele AI modellen en APIs vanaf je computer, telefoon, of tablet. Je installeert en gebruikt ChatboxAI grotendeels op dezelfde manier op al je apparaten:
Stap 1
Download ChatboxAI vanaf https://chatboxai.app of de link hieronder. Open het gedownloade bestand en doorloop de installatie.
Stap 2
Chatbox start doorgaans automatisch, zo niet, start het dan op. Je krijgt nu een automatische configuratiewizard te zien en kunt eventueel de instellingen altijd aanpassen via het ‘Settings’-tandwiel. Pas de volgende gegevens aan:
- API Host: Pas dit enkel aan als je Ollama vanaf een ander apparaat gebruikt dan het apparaat waar je het op host. Wijzig in dat geval het local host IP-adres http://127.0.0.1:11434 naar het externe IP-adres van je server/computer, bijvoorbeeld http://123.123.123.213:11434.
- Model: Selecteer het gewenste Ollama-model. Je kunt dit later altijd aanpassen in een chatsessie.

Je kunt nu direct aan de slag met Ollama via Chatboxai. Er zijn al een paar voorbeelden automatisch opgenomen in Chatbox waarin het model een instructie mee heeft gekregen, zoals in het voorbeeld hieronder waarin het gekozen LLM de instructie krijgt om zich te gedragen als een softwareontwikkelaar.

API
Een van de handigste features van Ollama is dat je zonder kosten gebruik kunt maken van een API om modellen in je eigen project te integreren. Als kers op de taart werkt dit ook nog relatief eenvoudig. Hieronder geven we een Python voorbeeld.
Vereisten
- Python (een up-to-date versie): Veel besturingssystemen ondersteunen python out-of-the-box en de installatie valt dan ook buiten de scope van deze handleiding.
- De OpenAI module voor Python: Installeer de module via een terminal/cmd met het commando: pip install openai
De basics
Stap 1
Maak een .py-bestand aan (bijv ai.py) en voeg de volgende code toe (vervang deepseek-r1:32b door je gekozen model):
import openai
client = openai.Client(
base_url="http://127.0.0.1:11434/v1",
api_key="ollama"
)
response = client.chat.completions.create(
model="deepseek-r1:32b",
messages=[{"role": "system", "content": "You're a helpful assistant."},{"role": "user", "content": "Hello"}],
temperature=0.7
)
print(response.choices[0].message.content)- Pas optioneel 127.0.0.1 aan naar het publieke IP-adres van je server en 32b (achter model =) naar het aantal parameters van het gebruikte model.
- “You're a helpful assistant.” is de instructie voor het model voor de chat begint. Je bent vrij dit een stuk uitgebreider te maken.
- “Hello" is jouw prompt/vraag aan je gekozen model. Pas dit uiteraard ook naar wens aan.
- Het print-commando zorgt ervoor dat de output in je terminal getoond wordt.
Stap 2
Voer het .py bestand uit, bijvoorbeeld (in Windows):
c:\Ollama>ai.pyDe output ziet er ongeveer als volgt uit:
<think>
Okay, the user asked me to act as a helpful assistant. I need to respond in a friendly and approachable way. Maybe say something like, "I'm here to help! How can I assist you today?" That should cover it.
</think>
Hello! I'm here to help. What do you need assistance with?So far so good: Ollama laat zijn gedachte zien en die zal bij herhaaldelijk gebruik van dezelfde prompt variëren. Maar… na het uitvoeren van ai.py wordt eenmaal het script uitgevoerd en afgesloten. Hoe kun je in een terminal een doorlopende chatsessie voeren? Dat brengt ons bij de volgende paragraaf
Een doorlopend gesprek voeren
Na de basics ben je al een heel eind. Voor het gemak laten we hieronder nog een voorbeeld zien hoe je een doorlopend gesprek voert, met dank aan DeepSeek die zelf dit voorbeeld genereerde:
import openai
# Create the client
client = openai.Client(
base_url="http://127.0.0.1:11434/v1",
api_key="ollama"
)
# Start your conversation history
messages = [
{"role": "system", "content": "You're a helpful assistant."}
]
while True:
# Ask for user input
user_input = input("User: ")
# If user types something like 'exit' or 'quit', break out
if user_input.lower().strip() in ["exitchat", "quitchat"]:
print("Exiting...")
break
# Add the user's message to the conversation
messages.append({"role": "user", "content": user_input})
# Generate assistant response
response = client.chat.completions.create(
model="deepseek-r1:32b",
messages=messages,
temperature=0.7
)
# Grab the assistant's reply
assistant_reply = response.choices[0].message.content
print("Assistant:", assistant_reply)
# Append assistant message to the conversation so context is maintained
messages.append({"role": "assistant", "content": assistant_reply})- Pas optioneel 127.0.0.1 aan naar het publieke IP-adres van je server en het gekozen model (achter model =) aan naar het gewenste model.
- “You're a helpful assistant.” is de instructie voor het model voor de chat begint. Je bent vrij dit een stuk uitgebreider te maken.
- “User:" geeft aan dat dit is waar jouw input komt
- exitchat en quitchat sluiten de chatsessie af
Voer het .py bestand uit, bijvoorbeeld (in Windows):
c:\Ollama>ai.pyDeze keer kun je daadwerkelijk een chat-sessie voeren met je gekozen model. Pas op: het denkproces (<think>….</think>) kan behoorlijk uitgebreid zijn.
Daarmee zijn we aan het eind gekomen van deze handleiding over het zelf hosten van Ollama. Veel succes!