SEO: leren van andermans fouten
Deze keer een extra speciaal artikel, namelijk het eerste gastartikel op het TransIP Blog! Met liefde geschreven door niemand minder dan SEO-specialist en digitale nomade Romano Groenewoud, ook bekend onder de naam SEO Geek. Hij neemt ons mee in de wereld van zoekmachineoptimalisatie en wijst ons op punten waarbij extra voorzichtigheid geboden is. We wensen je veel leesplezier en mocht je zelf staan te springen om wat te delen over jouw vakgebied, laat het ons weten en wie weet word jij onze volgende gastauteur!
SEO-bloopers ter lering ende vermaeck
Velen van ons kunnen een heel dagdeel besteden aan het bekijken van YouTubefilmpjes omtrent bloopers. Wat heeft SEO hiermee te maken zal je denken; dat is toch een vakgebied waar nooit wat mis kan gaan? Nou in dit artikel lichten we een aantal cases toe, onder het mom ter lering ende vermaeck.
De aanleiding van het schrijven van dit artikel is een recente fout van LinkedIn. Van de ene op de andere dag was de hoofdversie van de website van LinkedIn, namelijk die op het www-protocol, totaal verdwenen uit alle zoekresultaten. SEO-specialisten dachten gelijk aan een Googlesanctie; wellicht had LinkedIn bijzondere veranderingen doorgevoerd en was het om die reden op de vingers getikt. Of toch een bug aan Google haar zijde? Niets van dat alles. Hoewel de betrokkenen geen uitsluitsel gegeven hebben, is het waarschijnlijk misgegaan bij de uitvoering van een Google Search Console-rapport. Achter de schermen zou dit er ongeveer zo uitgezien moeten hebben:
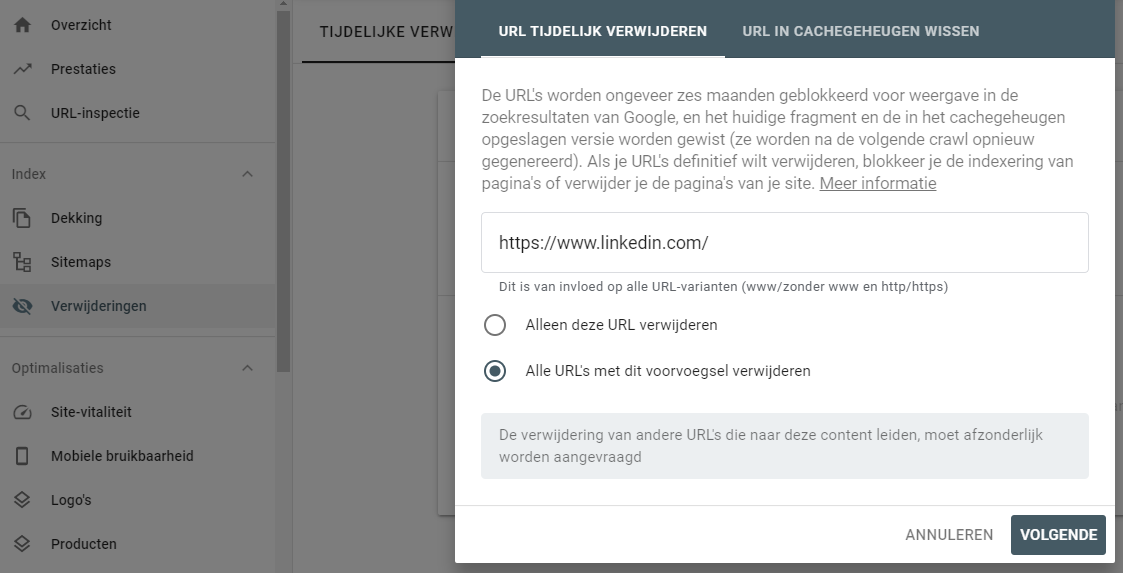
Dit rapport van Google Search Console is met name nuttig voor wanneer er paginas van jouw website in de Google-index staan die je er zo snel mogelijk uit wilt hebben. Een praktisch voorbeeld daarvan is bijvoorbeeld een verstreken pagina omtrent een korting of winactie. Je wilt niet langer dat mensen je daarop vinden in Google en middels deze functionaliteit kan je rap de betreffende pagina(s) uit de index halen.
Het lijkt erop (nogmaals we weten dit niet helemaal zeker) dat LinkedIn wilde overstappen naar een weergave in de zoekresultaten zonder www. in de URL. Dus https://linkedin.com i.p.v. https://www.linkedin.com.
Les geleerd: indien je wilt overstappen van URLs met www naar URLs zonder www in de zoekresultaten, gebruik dan niet de verwijderingstool uit de Google Search Console! Een redirect met een 301-statuscode via een .htaccess-bestand is een betere manier om dit doel te bereiken (al dan niet vergezeld met canonical tags en een propere sitemap). In veel CMS'en zoals WordPress is er vaak zelfs een optie in de backend om aan te geven wat je www-voorkeuren zijn. Voorheen kon dit alles nog via Google Search Console ingericht worden, maar die optie is niet meer aanwezig in de nieuwste versie.
Gelukkig dendexeren de functies uit het Google Search Console-rapport de URLs niet, maar worden ze alleen tijdelijk verborgen en kan het dus ook zo weer worden teruggedraaid. Binnen een dag was het immers alweer opgelost bij LinkedIn.
De noindex-tag
Een andere veelvoorkomende fout met meer desastreuze gevolgen is het verkeerd gebruik van de noindex-tag. De noindex-tag is bijvoorbeeld een goed idee voor de ontwikkeling van een nieuwe website die je nog niet aan de buitenwereld wilt tonen. Wanneer die website af is en je trots je nieuwe creatie ten tonele wilt brengen, dan is het wel zaak om die noindex-tag weer weg te halen om je website in Google te laten verschijnen.
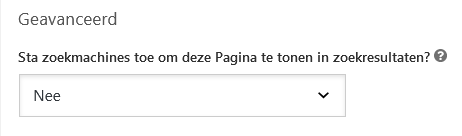
Het toevoegen of verwijderen van deze tag wordt tegenwoordig steeds makkelijker. Zoals je in bovenstaande afbeelding kunt zien, rept de populaire WordPress-plug-in Yoast SEO geeneens over de term 'noindex, maar legt het de werking van de tag uit in simpele taal. In de meeste moderne websitesystemen zal dit vandaag de dag het geval zijn.
Indien je vergeet de noindex-tag te verwijderen en het gaat om een nieuwe website, is er weinig verloren. De daadwerkelijke lancering heeft alleen wat uitstel opgelopen. Het per ongeluk plaatsen van een noindex-tag op een bestaande gevestigde website kan wel nare gevolgen hebben. Na het verwijderen van de tag zullen verdwenen paginas uiteindelijk wel weer in Google verschijnen, maar daar kunnen soms weken overheen gaan. Vooral als het gaat om een kleinere, minder bekende website van een zzp- of mkb-organisatie.
De disallow-functie
Dan is er ook nog de disallow-functie in het robots.txt-bestand. Het robots.txt-bestand vind je doorgaans op domeinnaam.nl/robots.txt. Dit vertelt crawlers (zoals Googlebot) waar ze mogen komen op de website en waar niet. Let wel, dit is wat anders dan een noindex-tag. Een noindex-tag is een expliciet gebod dat Google een bepaalde pagina uit de index moet halen. Bij een disallow middels het robots.txt-bestand vertel je alleen dat de crawler bepaalde paginas moet overslaan. Maar het kan nog wel zo zijn dat andere websites naar jouw paginas linken en je paginas via een omweg alsnog door Google wordt gendexeerd! Een voorbeeld van een robots.txt-bestand van de website AD:
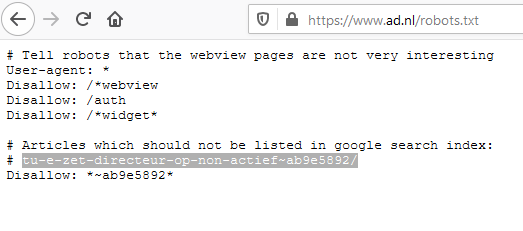
Blijkbaar wilden zij een bepaald artikel uit de index van Google halen, en dat is gelukt. Maar een betere benadering is om een noindex-tag op de betreffende URL te plaatsen en de verwijderingstool uit Google Search Console te raadplegen.
Doorgaans komt de volgende blooper nog vaak voor: een webdesigner laat per ongeluk de volgende code staan:User-agent: googlebot
Disallow: /
Wat je hiermee doet, is alle bots (ook wel spiders genoemd) van specifiek Google beletten de gehele website te crawlen. Indien Google niet belangrijk voor je is, is dit prima. Maar indien je gebaat bent bij organisch zoekverkeer, een slecht idee.
Een andere veel gemaakte fout is een conflict laten ontstaan tussen de disallow-functie in robots.txt en de noindex-tag. Je kunt ze beter niet gezamenlijk inzetten. Middels de disallow-functie belet je de zoekmachinecrawler van het benaderen van een bepaalde pagina. Maar als de spider deze pagina overslaat, dan kan deze ook niet de noindex-tag op deze pagina observeren en naar gelang handelen. De noindex-tag voor die pagina is dan in principe nutteloos.
De hreflang-tag
Een van de meest complexe onderdelen van technische SEO zijn hreflang-tags. Je vindt ze in de headsectie van een pagina en ze zien er als volgt uit:
<link rel="alternate" hreflang="nl-nl" href="https://www.PaulsKeuken.nl/spaghetti-recepten" />
<link rel="alternate" hreflang="nl-be" href="https://www.PaulsKeuken.be/spaghetti-recepten" />
Op zich geen hogere wiskunde toch? Zeker als je enig verstand hebt van HTML. Hoe kan het dan toch zo vaak misgaan? Er zijn een paar niet intutief aanvoelende vereisten aan hreflang-tags. Wanneer deze niet tot de letter gevolgd worden, stort alles als een kaartenhuis in elkaar.
De eerste regel die vaak misgaat, is dat men altijd dient te beginnen in de tag met de taalafkorting en dan pas het land. Start je eerst met het land en dan pas de taal dan kan het zijn dat je een targeting instelt die je totaal niet wilt. Een simpel voorbeeld is nl-be. Je dacht waarschijnlijk, dat zal wel de code zijn om Vlaamse bezoekers te adresseren, toch? Nee, hiermee zou je Nederlandssprekenden in Wit-Rusland (Belarus) aanspreken wat betreft de zoekmachines. Kans is aanzienlijk dat jouw doelgroep niet bestaat uit Nederlandse expats in Wit-Rusland.
Dit voorbeeld ben ik daadwerkelijk tegengekomen in mijn werk als SEO-specialist zijnde. Het gevolg? De NL-versie van de website deed het prima tot dusver in Google.nl. Maar de BE-website heeft nooit echt een voet tussen de deur kunnen krijgen in Google.be-zoekresultaten. Na het corrigeren van deze fout van de webdesigner in kwestie, duurde het ongeveer twee tot vier weken tot we mooie resultaten gingen zien van de BE-website, die overigens prima was qua optimalisatie. Na een maand stond men zelfs in de top 3 voor de meest belangrijke zoektermen zonder verdere significante aanpassingen of verbeteringen.
URL-structuur
Een andere fout ontstaat bij het migreren naar een nieuw websitesysteem en daarbij gepaard gaande nieuwe URLs. Zo komt het regelmatig voor dat vergeten wordt de oude URLs door te verwijzen naar de nieuwe versie.
Laat ik het eerder gedeelde voorbeeld nog eens gebruiken, PaulsKeuken.nl/spaghetti-recepten. Stel dat Paul nou besluit dat om wat voor reden dan ook dit beter zou kunnen zijn: PaulsKeuken.nl/pasta-recepten. Paul moet dan PaulsKeuken.nl/spaghetti-recepten met een 301-statuscode doorverwijzen (redirecten) naar de nieuwe URL. De meeste websitesystemen hebben hier modules voor, zoals hieronder afgebeeld, en anders is dit handmatig te regelen in het zogenaamde .htaccess-bestand.
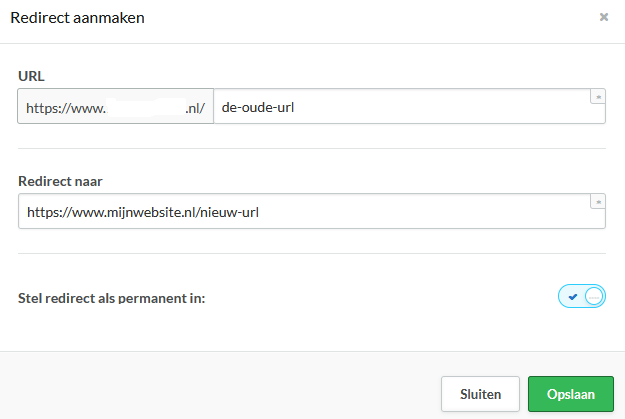
De 301-statuscode betekent voor Google dat er sprake is van een permanente verhuizing en dat alle voor zoekmachines belangrijke signalen doorgegeven dienen te worden. Denk aan belangrijke links vanuit andere websites, sociale shares, enzovoort. Doe je dit niet, dan begint de nieuwe URL in principe vanaf nul en is het maar de vraag of een website een sterke positie in de zoekresultaten behoudt. Bekende gevallen in Nederland waar dit misging, waren bijvoorbeeld de websites van Transavia en de Rabobank.
Google zelf
De makers achter de zoekmachine, zelfs zij maken fouten. Het is immers een enorm bedrijf met tientallen afdelingen die soms volledig (bewust) gesoleerd van elkaar opereren. Een van de geboden van SEO opgeven door Google is dat je nooit, onder geen beding, mag betalen voor links vanuit andere websites richting je eigen website. Toch gebeurde het: aandachtige SEO-specialisten viel op dat er betaalde links gingen richting de website van de Google Chrome-browser. En dus kreeg een Google-website een sanctie, ofwel een penalty in de volksmond opgelegd door Google! Twee maanden lang leed de homepage aan een handmatige sanctie (dit is in SEO-jargon een situatie waarbij je handmatig door een Google-medewerker een straf opgelegd krijgt).
Een ander vergrijp van Google was de keer dat ze content hebben gecloaked op kennisbankartikelen van de Google AdWords-website (tegenwoordig heet dat Google Ads). Cloaken is wanneer tekst niet zichtbaar is voor bezoekers maar wel voor zoekmachines. Dit is een ernstig vergrijp, omdat dit zoekmachinemanipulatie is. Ook in dit geval bestrafte Google zichzelf. Het is bemoedigend om te zien dat de zoekmachinegigant zichzelf niet de dans laat ontspringen.
Ondergetekende maakt ook fouten
En de schrijver van dit artikel, maakt die nooit fouten? Eerlijkheid gebiedt te zeggen dat ik nooit dit soort fouten heb gemaakt. Maar wat nog niet is, kan nog komen. Natuurlijk zijn er wel zaken waarop ik terugkijk en waarvan ik denk, goh, dat had ik toch anders aan moeten pakken. Zoals uit de voorbeelden hierboven blijkt, is niemand perfect.
Ik zou dit artikel dan toch op een positieve noot willen afsluiten met een welbekende quote van niemand minder dan Michael Jordan, de basketballegende:
I've missed more than 9000 shots in my career. I've lost almost 300 games. 26 times, I've been trusted to take the game winning shot and missed. I've failed over and over and over again in my life. And that is why I succeed.
Fouten maken ook ons SEO-specialisten, online marketeers en internetondernemers sterker. Laat het je dus zeker niet ontmoedigen. Al is het altijd fijner en leuker om te leren van andermans fouten natuurlijk.
Bedankt voor het toelichten!